
TheFablab è attivo dal 2014 nell'ambito dell'educazione tecnologica e della fabbricazione digitale, progettando percorsi formativi per i giovani e le comunità. Collabora a progetti nazionali con aziende, enti pubblici, scuole e istituzioni culturali per promuovere le competenze STEM, l'alfabetizzazione digitale e la cultura scientifica. Attraverso programmi educativi hands-on, contribuisce a rafforzare il capitale scientifico delle nuove generazioni e l'approccio critico verso le tecnologie emergenti, sostenendo l'empowerment, l'inclusione e il benessere educativo.
Le applicazioni pratiche del machine learning sono tra gli esempi più lampanti dell’integrazione dell’Intelligenza Artificiale nella quotidianità di ognuno di noi. Dall’algoritmo di social media come TikTok ai Daily Mix di Spotify, il machine learning ha già da tempo un impatto concreto su quello che ascoltiamo, guardiamo e acquistiamo tutti i giorni.
Comprendere il funzionamento degli algoritmi di machine learning, quindi, è importante non solo per costruire un futuro lavorativo nel mondo dell’informatica e della programmazione, ma anche, in un’ottica di cittadinanza attiva, per trasformare gli studenti da semplici utenti della tecnologia in critici consapevoli e informati.
Per contribuire a raggiungere questo obiettivo, Google ha sviluppato Teachable Machine, uno strumento web based che permette di addestrare modelli di Machine Learning in pochi minuti, direttamente dal browser. Teachable Machine è un’applicazione no-code: non è necessario saper programmare per usarlo e sperimentare. Questa caratteristica abbatte le barriere in ingresso alla tecnologia, consentendo un uso trasversale con studenti di livello diverso, ma può rivelarsi utile anche per chi sa già programmare. In quanto ambiente di sperimentazione rapida che rende immediatamente visibili concetti complessi, infatti, Google Teachable Machines permette di isolare la variabile più critica del processo di machine learning: il dato.
Nel machine learning la sfida non è più solo creare l’algoritmo perfetto, ma anche e soprattutto curare l’ambiente informativo da cui l’algoritmo trae le proprie conclusioni. In questo contesto, l’enfasi si sposta dalla sintassi del codice alla qualità delle informazioni. Google Teachable Machine rende evidente questo aspetto, permettendo di isolare il processo di apprendimento della macchina e di rendere visibile come ogni variazione nel set di dati influenzi il comportamento dell’algoritmo.
Sotto la superficie: come funziona Google Teachable Machines
Teachable Machine si basa su TensorFlow.js, una libreria che permette di eseguire l’addestramento sfruttando la potenza di calcolo locale dell’utente, garantendo così velocità e privacy. Il cuore tecnologico dello strumento è il Transfer Learning (“apprendimento per trasferimento”), una tecnica che consiste nel riutilizzare un modello di Intelligenza Artificiale già addestrato su compiti generici per svolgere compiti più specifici. Google Teachable Machine utilizza un modello pre-addestrato chiamato MobileNet, addestrato sul gigantesco dataset ImageNet. Gli strati più profondi della rete neurale non vengono alterati da Teachable Machine, che addestra solo un piccolo strato finale, chiamato classifier o head.
Lo strumento agisce su tre tipologie di input:
- Immagini. Classificazione di oggetti, volti o scenari tramite webcam o il caricamento di file.
- Suoni. Riconoscimento di campioni audio di un secondo, basato sulla visualizzazione dello spettrogramma sonoro.
- Pose. Utilizzo di librerie come PoseNet per mappare i punti nodali del corpo umano (spalle, gomiti, ginocchia) e riconoscere movimenti o posizioni specifiche.
L’utilizzo si divide a sua volta in tre fasi: la raccolta dei campioni, l’addestramento del modello e l’esportazione del progetto finale.
Google Teachable Machine come laboratorio per l’apprendimento: un esempio di attività pratica
Un’applicazione semplice e immediata di Google Teachable Machine è lo sviluppo di una serratura vocale. Siamo abituati a pensare alle password come a sequenze di caratteri digitate su tastiera, ma la moderna cybersecurity si sta orientando sempre più verso la biometria, dove il segnale è un tratto biologico (in questo caso, la voce).
In questa attività, la tua classe addestrerà Google Teachable Machine a riconoscere un’impronta vocale specifica, osservando come piccoli dettagli nel modo in cui sono raccolti i campioni possono fare la differenza tra un sistema sicuro e uno facilmente ingannabile.
Per prima cosa, iniziate un progetto di tipo Audio su Google Teachable Machine. Il lavoro può essere suddiviso in quattro step:
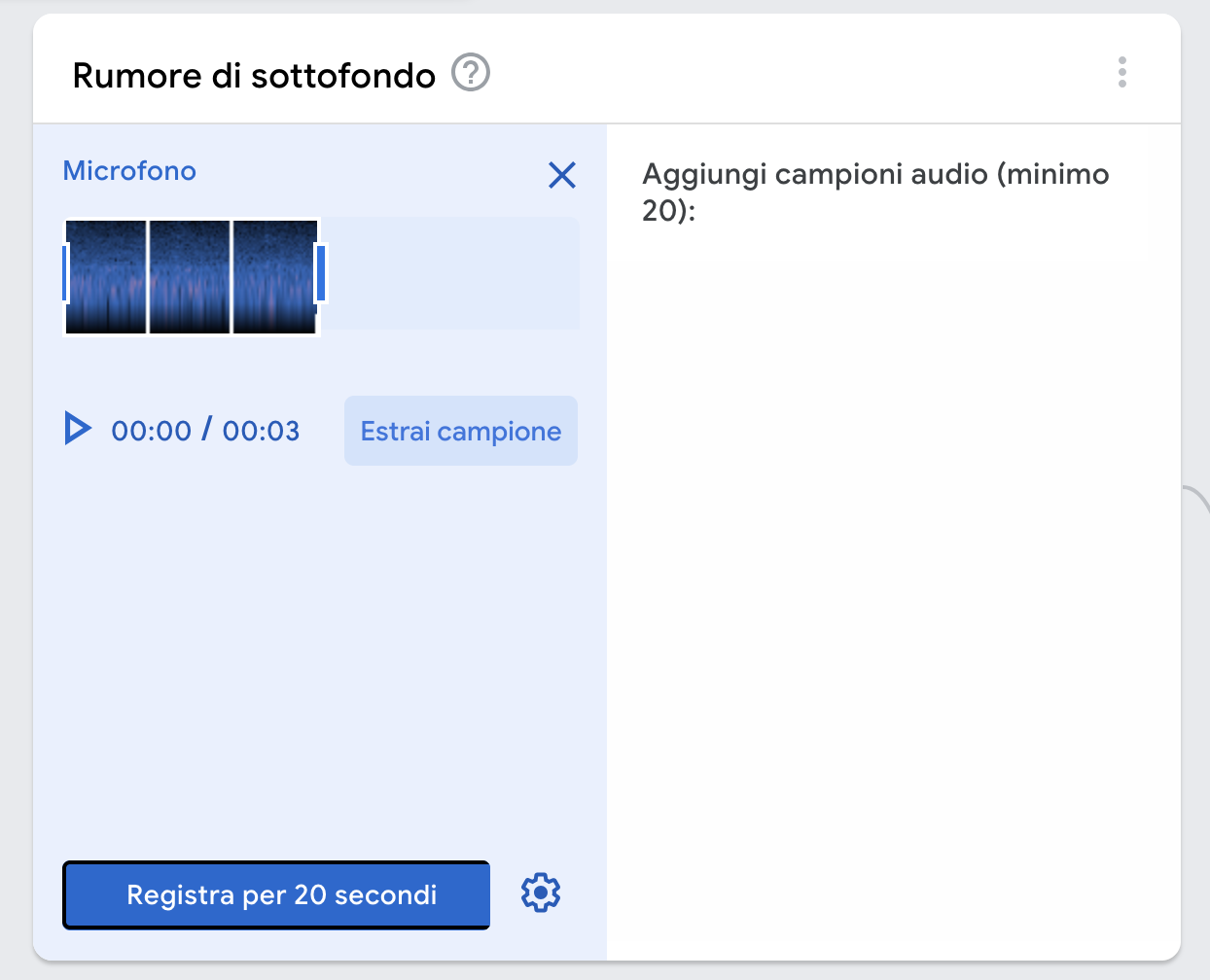
1. Mappatura del rumore di fondo. Per evitare che l’algoritmo interpreti il brusio dell’aula come un tentativo di accesso al sistema di riconoscimento, addestrate lo strumento a riconoscere il rumore di fondo. Tutti i progetti audio di Google Teachable Machine devono avere una registrazione del rumore di fondo di almeno 20 secondi. Più intenso sarà il rumore di fondo dell’aula, più sarà complesso per il sistema distinguere i comandi vocali.
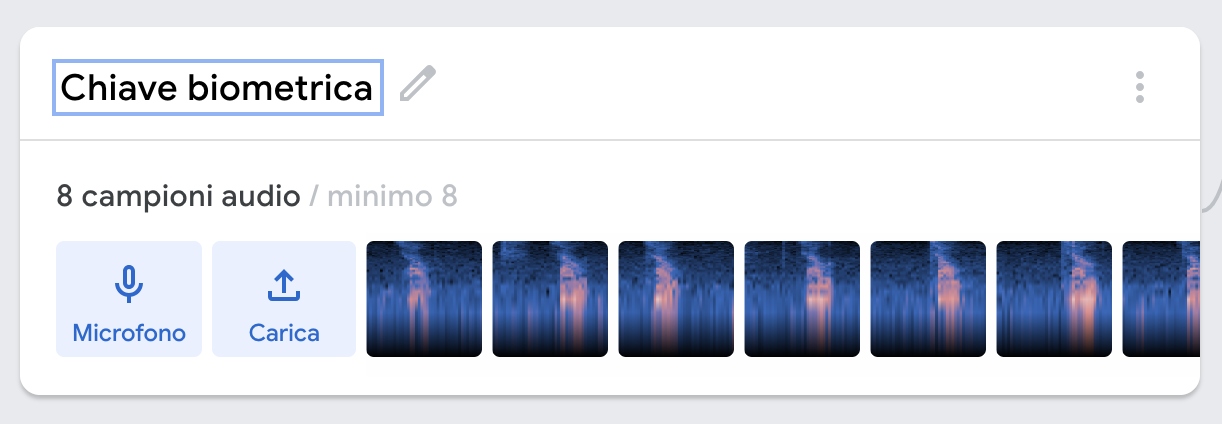
2. Creazione della chiave biometrica. Scegliete uno studente che sarà incaricato di registrare la parola che avete scelto come password. Chiamate la Classe 2 “Chiave biometrica” e registrate i campioni di audio corrispondenti: in questa fase, il sistema ha bisogno di almeno 8 campioni.
Quando avrete registrato tutti i campioni, passate alla fase di addestramento per un primo test sul funzionamento del modello. Verificate se il sistema riesce a distinguere in modo netto la parola chiave pronunciata dallo studente prescelto dal rumore di fondo. Se non siete soddisfatti del risultato, potete provare a registrare più campioni e addestrare nuovamente il modello: le dimensioni del dataset hanno un impatto concreto sulla qualità del riconoscimento.
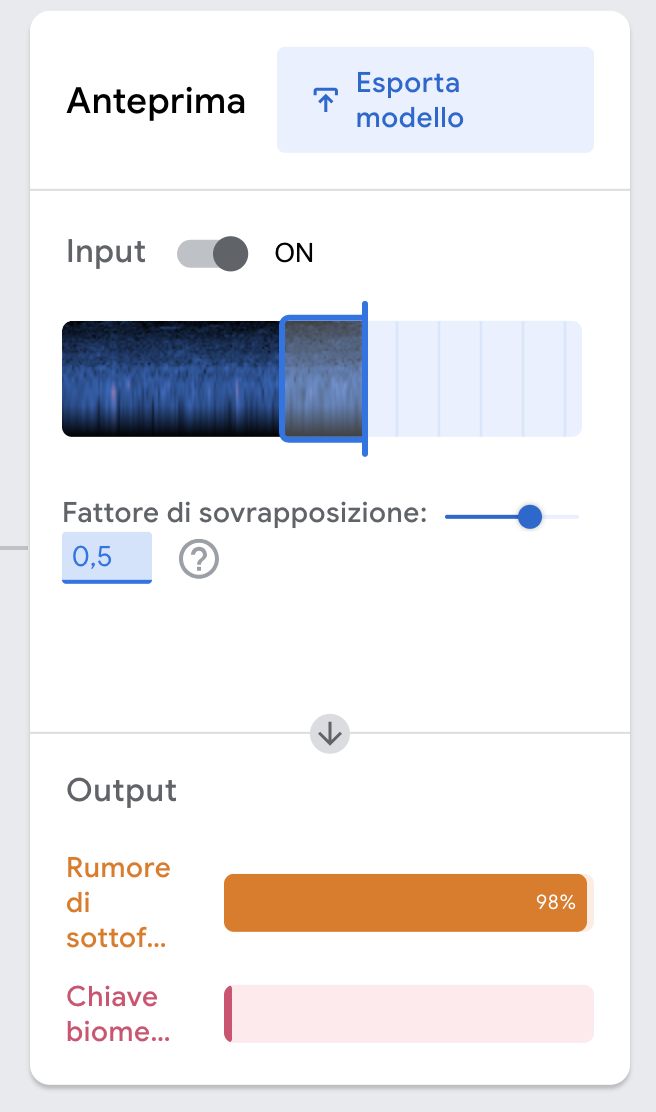
Il fattore di sovrapposizione visualizzato in questa fase riflette la frequenza con cui l’IA ascolta l’ambiente per cercare di riconoscere un suono. Il programma, infatti, non ascolta un flusso continuo di audio, ma scatta delle “istantanee sonore” della durata di un secondo. Questo parametro stabilisce quanto ogni istantanea si sovrappone alla precedente.
Un fattore di sovrapposizione basso può rendere problematico il riconoscimento di password molto brevi, mentre il fattore alto aiuta a rendere il sistema più reattivo.
Sperimentate con il valore del fattore di sovrapposizione per osservare i cambiamenti nella reattività del modello. Noterete che per fattori vicini a 1 la barra della confidenza sale in modo fluido mentre parlate, quasi come se il sistema stesse ascoltando in modo continuo.
3. Test dell’intruso. Aumentate la complessità del sistema aggiungendo al progetto una nuova classe, che chiamerete “Intruso”. Per addestrare questa classe, fate registrare ad altri studenti la parola scelta come password. L’obiettivo è insegnare all’algoritmo a distinguere non solo il contenuto del messaggio, ma anche il timbro e la frequenza, definendo i confini tra utente autorizzato e intruso.

4. Stress-test. Una volta addestrato il modello con la nuova classe, provate a metterlo in difficoltà per testare la sua effettiva sicurezza. Cosa succede se lo studente che ha addestrato la classe “Chiave biometrica” prova a camuffare la propria voce? O se l’intruso usa una registrazione della voce del proprietario?
Al termine dell’attività, esportate il modello per salvarlo su Google Drive o per integrarlo in siti web o altre applicazioni.
Indice