
Questo articolo esplora l'uso dell'intelligenza artificiale (IA) nella compressione delle immagini, confrontando metodi tradizionali come JPEG con approcci più avanzati basati su reti neurali. Mentre la compressione tradizionale si limita a ridurre i dettagli visivi meno significativi, l'IA mira a emulare il funzionamento del cervello umano, comprimendo le immagini in modo più efficiente, mantenendo solo le informazioni percepibili dall'occhio umano. Si analizza il concetto di entropia percettiva, che consente di ridurre lo spazio necessario per memorizzare un'immagine senza perdere la qualità visiva. L'articolo descrive inoltre tecniche avanzate come gli autoencoder e la quantizzazione vettoriale, illustrando come queste possano ottenere una compressione molto più efficace rispetto ai metodi tradizionali. Nonostante i promettenti risultati in termini di qualità visiva, la compressione IA presenta ancora limiti legati ai costi computazionali e alla mancanza di standardizzazione. L'articolo include anche attività pratiche per confrontare le prestazioni dei diversi metodi di compressione e riflessioni sulla necessità di nuove metriche percettive.
Hai mai pensato a quante immagini vedi ogni giorno? Milioni. Eppure il nostro cervello sembra avere una capacità quasi infinita di ricordarle. Come fa? In realtà, due fattori principali contribuiscono a questa abilità:
1. Alta capacità di memorizzazione: il cervello può immagazzinare enormi quantità di informazioni.
2. Algoritmo di compressione intelligente: a differenza dei metodi tradizionali come JPEG, il cervello non memorizza ogni dettaglio pixel per pixel. Analizza e conserva ciò che è veramente importante per la percezione visiva.
Questa osservazione apre una domanda affascinante: possiamo creare algoritmi simili con le reti neurali artificiali per comprimere immagini, permettendo di memorizzare quantità enormi di dati su un singolo computer?
Compressione Tradizionale vs Compressione Intelligente
Il formato JPEG, ad esempio, è onnipresente sul web. Funziona riducendo informazioni come i dettagli ad alta frequenza e modificando la risoluzione del colore, mantenendo però un aspetto visivo quasi identico. Il problema è che JPEG non comprende cosa rappresenta l’immagine, memorizza solo i dati grezzi in modo più efficiente.

Il cervello, invece, ricorda concetti e relazioni tra gli oggetti. Se ti viene chiesto di ricordare un’immagine, probabilmente ricorderai un albero e un cielo, ma non la posizione precisa di ogni foglia o dettaglio di texture. Questo suggerisce che un algoritmo di compressione ottimale dovrebbe capire quello che è percepibile dall’occhio umano e scartare tutto il resto.

Il Ruolo dell’Entropia nella Compressione dei Dati
Per capire meglio come comprimere i dati, entra in gioco il concetto di entropia. In fisica, l’entropia misura il disordine; nella teoria dell’informazione, misura la quantità minima di dati necessari per descrivere un’informazione.
- Un’immagine semplice ha bassa entropia: basta descrivere poche informazioni per ricostruirla.
- Un’immagine più complessa ha alta entropia: serve più informazione per descrivere ogni dettaglio.
Il compito della compressione è rappresentare i dati in una dimensione vicina alla loro entropia, ovvero ridurre lo spazio occupato senza perdere le informazioni percepite come importanti.
Entropia Percettiva e Compressione IA
Esiste un concetto ancora più potente: l’entropia percettiva. Due immagini possono differire pixel per pixel, ma essere visivamente identiche per l’occhio umano. Un algoritmo di compressione ideale dovrebbe basarsi sull’entropia percettiva, eliminando le differenze impercettibili e mantenendo solo ciò che conta per la nostra percezione.
Le reti neurali e la compressione IA funzionano proprio così. Studiano come il cervello codifica le informazioni visive e cercano di emularlo, permettendo una compressione molto più efficiente rispetto ai metodi tradizionali.
In questo articolo esploreremo il funzionamento degli autoencoder e della quantizzazione vettoriale, due concetti chiave per la compressione IA.
Cos'é un Autoencoder
Un autoencoder è una rete neurale progettata per ricreare i dati che riceve in input. Per esempio, se l’input è un’immagine, l’autoencoder cerca di generare un’immagine identica all’originale.
La caratteristica principale è che al centro della rete si trova uno strato intermedio molto più piccolo dei dati originali, chiamato spazio latente. Durante l’addestramento, l’autoencoder impara a comprimere l’immagine in questo spazio ridotto e poi a ricostruirla quasi perfettamente.
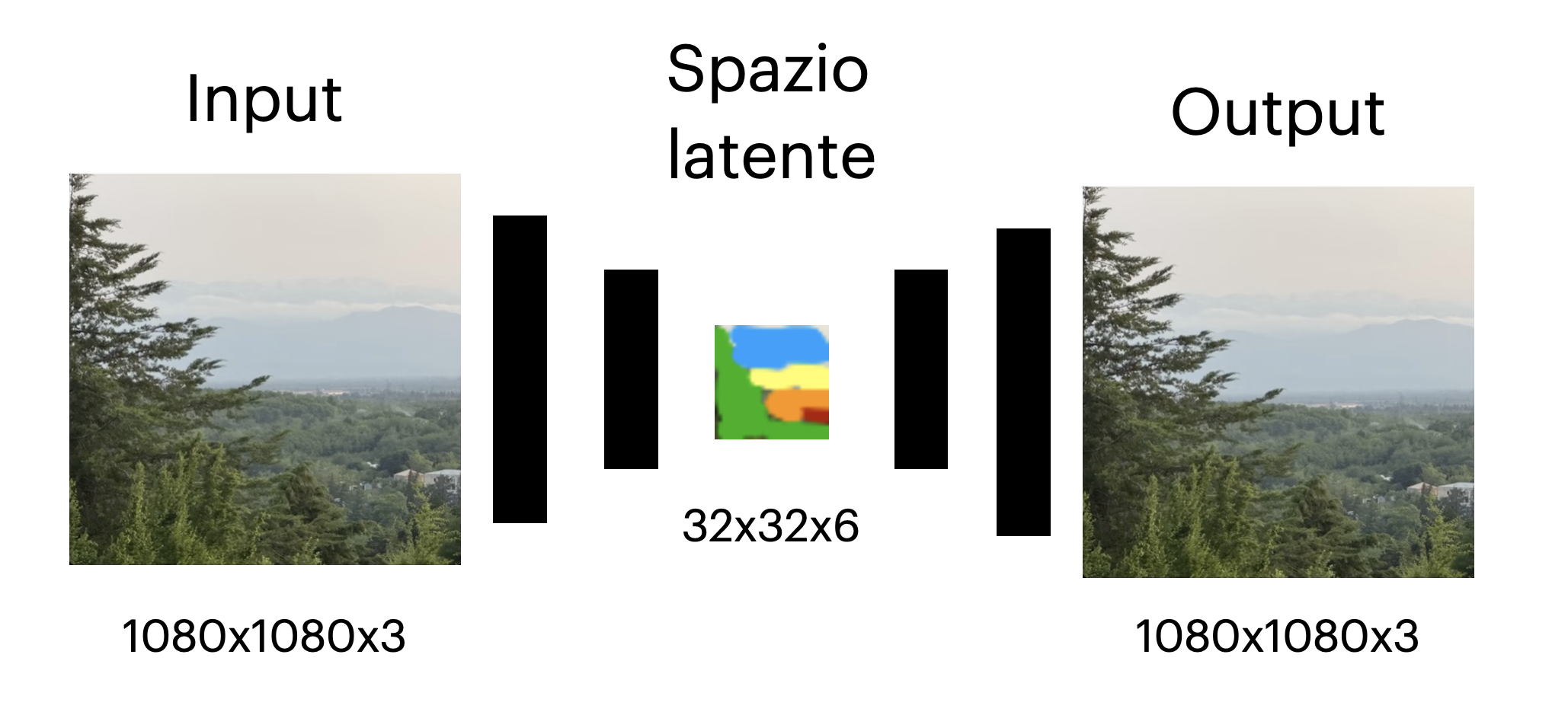
Perché un autoencoder da solo non basta
Anche se lo spazio latente ha meno numeri rispetto ai pixel originali, i valori che contiene sono numeri decimali ad alta precisione. Ogni numero richiede molti bit per essere memorizzato in un computer, quindi in pratica non si ottiene ancora una vera compressione.
Per ridurre lo spazio necessario a memorizzare questi numeri serve un processo chiamato quantizzazione, che consiste nel limitare i valori a numeri più semplici, tipicamente interi.
Quantizzazione e Percezione Umana
La quantizzazione semplice, come tagliare le cifre decimali, riduce le dimensioni del file ma può degradare la qualità dell’immagine. L’idea alla base della compressione IA è insegnare al modello a quantizzare in modo intelligente, preservando solo le informazioni percepibili dall’occhio umano.
Vector Quantized Autoencoder (VQ-AE)
Per ottenere una compressione efficiente, gli autoencoder possono essere trasformati in autoencoder a quantizzazione vettoriale (Vector Quantized Autoencoder, VQ-AE).
Come funziona
1. Lo spazio latente viene suddiviso in una griglia, ad esempio 32x32, dove ogni casella contiene un vettore di dimensione ridotta (es. 6 numeri).
2. Invece di memorizzare questi numeri decimali, ogni vettore viene associato a un simbolo preso da una palette di simboli, simile a una tavolozza di colori.
3. Ogni simbolo rappresenta concetti appresi dal modello (per esempio cielo, alberi o montagne) e può essere memorizzato come un piccolo numero intero, risparmiando moltissimi dati.
4. Durante l’addestramento, il modello confronta ogni vettore con i simboli nella palette e sostituisce il vettore con l’indice del simbolo più vicino. I simboli vengono aggiornati continuamente per rappresentare i pattern più comuni nelle immagini.
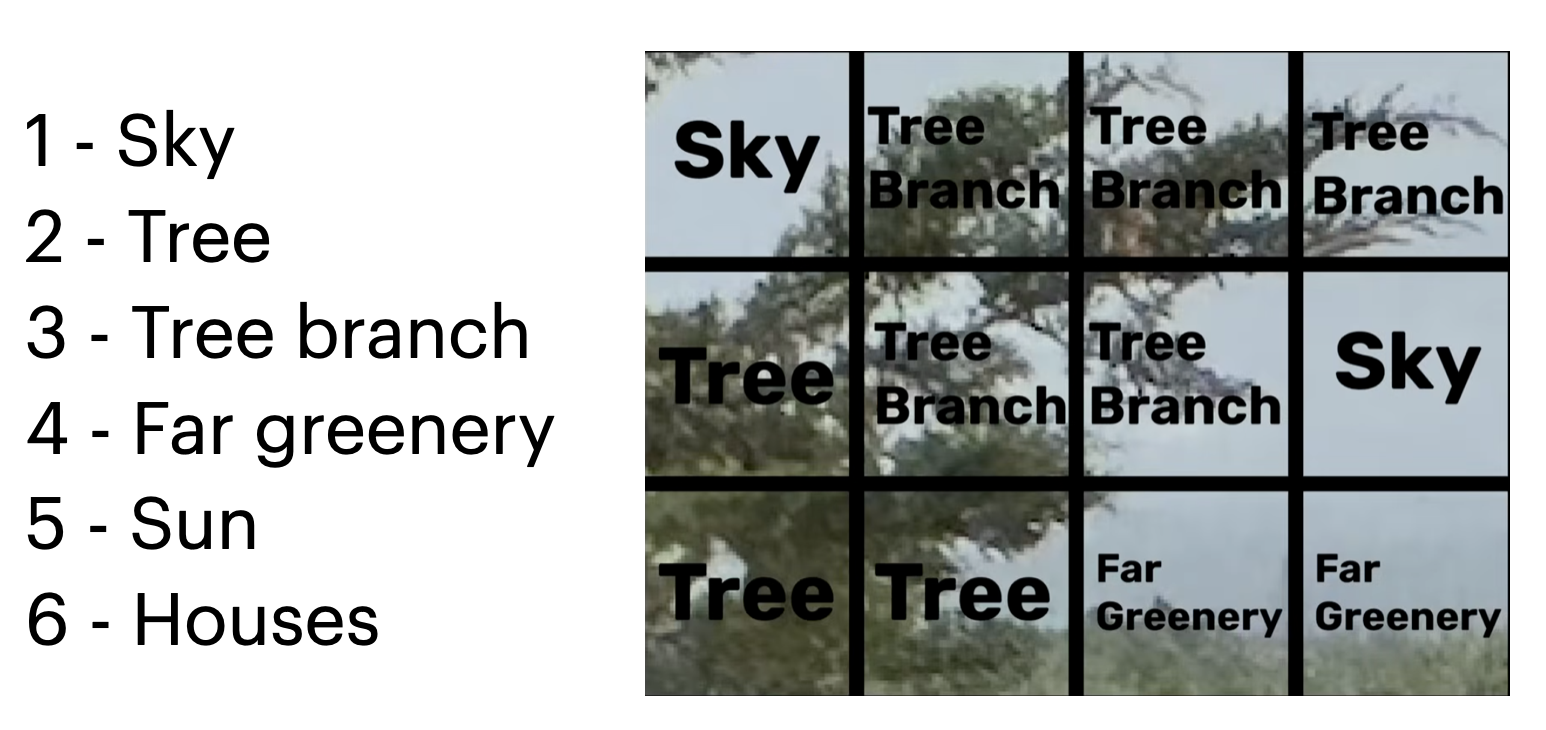
Il risultato è uno spazio latente simbolico, molto più piccolo dell’immagine originale, ma capace di ricostruirla quasi perfettamente. Lo spazio latente quantizzato contiene solo informazioni rilevanti per la percezione umana.
L’ultimo passo consiste nell’ottimizzare ulteriormente lo spazio necessario usando algoritmi di compressione classici. Questi algoritmi cercano di rappresentare i dati il più vicino possibile al limite teorico chiamato entropia. Alcuni esempi di tecniche sono:
- Codifica Huffman
- Codifica aritmetica
Combinando la quantizzazione appresa con la codifica dell’entropia, la compressione IA raggiunge livelli molto superiori rispetto ai metodi tradizionali come JPEG o PNG.
Esempi Pratici
Alcuni modelli di compressione di immagini con l’IA già esistenti dimostrano chiaramente quanto questa tecnologia possa essere potenti:
- Con lo stesso livello di compressione di JPEG, l’immagine ricostruita dall’IA può apparire quasi perfetta.
- A volte sembra persino “troppo perfetta”, perché l’IA può ricostruire dettagli plausibili che non erano presenti nell’immagine originale.
Questo dimostra che la compressione IA non solo riduce lo spazio dei file, ma preserva anche la qualità percepita dall’occhio umano.
Limiti attuali
Nonostante i risultati impressionanti, la compressione IA non è ancora uno standard universale per due motivi principali:
1. Costo computazionale elevato: richiede più tempo e risorse rispetto a JPEG o PNG.
2. Mancanza di standardizzazione: non esistono protocolli unificati per far sì che computer diversi usino lo stesso algoritmo.
Tuttavia, con il continuo aumento della potenza dei computer e lo sviluppo di standard, è probabile che la compressione IA diventerà lo standard del futuro.
Attività pratica n.1
Provare un algoritmo di compressione IA
Viene fornito il programma aicompression.py scritto in Python. Il codice proposto permette di caricare un’immagine, comprimerla:
- con il metodo JPEG,
- con un modello IA (CompressAI),
per poi confrontare i risultati.
Passaggi principali
1. Carica l’immagine originale e calcola la dimensione non compressa (in KB).
2. Applica la compressione JPEG, salvando un file .jpg leggibile e misurando la dimensione reale del file.
3. Applica la compressione IA: il modello neurale codifica l’immagine in un insieme di bitstream (stringhe di byte).
- La dimensione compressa viene stimata sommando la lunghezza dei bitstream.
- Non si ottiene un file “leggibile” sul computer, perché il contenuto è una rappresentazione interna del modello.
- Per la visualizzazione, il programma decodifica lo stream e salva l’immagine ricostruita in formato .png, così da poter confrontare i risultati visivamente.
4. Calcola le metriche PSNR e SSIM, confrontando l’immagine originale con le versioni ricostruite (JPEG e IA).
5. Mostra le tre immagini (originale, JPEG e IA) con le relative dimensioni e metriche.


PSNR JPEG: 29.911703626867222
PSNR IA: 16.6049522681423
SSIM JPEG: 0.8437300118302709
SSIM IA: 0.5212589855944176
Dimensione stimata immagine non compressa: 7810.5 KB
Dimensione file JPEG: 311.9 KB
Dimensione stream AI: 177.3 KB (stimati dai bitstream CompressAI)
Comprendere le misure di qualità
PSNR – Peak Signal-to-Noise Ratio
Misura quanto i pixel dell’immagine compressa differiscono da quelli originali.
Valori più alti indicano un’immagine più fedele (meno rumore).
Tuttavia, il PSNR non riflette la qualità percepita, ma solo l’errore numerico.
SSIM – Structural SIMilarity
Tiene conto di luminosità, contrasto e struttura locale.
È una misura più “intelligente” del PSNR, ma comunque legata alle somiglianze pixel per pixel.
Anche qui, un valore vicino a 1 indica alta somiglianza.
Interpretazione dei risultati
Durante l’esperimento si noterà che:
- L’immagine JPEG ottiene spesso PSNR e SSIM più alti.
- L’immagine IA, invece, appare più naturale e dettagliata, pur avendo valori numerici inferiori.
Questo accade perché le metriche tradizionali valutano differenze aritmetiche tra i pixel, mentre la rete neurale può ricostruire dettagli più realistici ma non identici ai pixel originali.
In altre parole, l’AI produce immagini percettivamente migliori, anche se numericamente più “diverse”.
Attività pratica n.2
Spunti di discussione o esercizi
1. Variare i parametri di qualità per JPEG (jpeg_quality) e IA (quality) e osservare come cambiano le dimensioni e la qualità.
2. Provare immagini diverse (ritratti, paesaggi, texture) e confrontare i risultati.
3. Riflettere: quale compressione “preferisce” l’occhio umano e quale “preferiscono” le metriche?
4. Discutere perché nel futuro potrebbero servire nuove metriche percettive, più coerenti con la qualità visiva umana.
Indice